На сайте используются файлы cookie. Продолжая использование сайта, Вы подтверждаете своё согласие на применение cookie в соответствии с нашей политикой.
ROBOTS.TXT - ПОЛНОЕ РУКОВОДСТВО
- Что такое файл robots.txt
- Что такое директивы в robots.txt?
- User-agent
- Disallow
- Allow
- Clean-param
- Crawl-delay
- Sitemap
- Устаревшая директива Host
- Прочие директивы robots.txt
- Использование регулярных выражений
- Комментирование в файле robots.txt
- Генерация robots.txt: плюсы и минусы
- Как проверить правильную работу файла robots.txt?
- robots.txt и CMS
- Типичные ошибки при составлении файла роботс txt
Что такое файл robots.txt
Robots.txt — это текстовый файл, предназначенный для регулирования поведения веб-краулеров на сайте (поисковых и прочих роботов). Данный файл можно создать в любом текстовом редакторе с расширением .txt и кодировкой UTF-8, доступен по протоколам http, https и ftp. Robots.txt должен располагается в корневом каталоге и быть доступным по адресу https://site.com/robots.txt/.
Внимание! Действие файла robots.txt не распространяется на поддомены. Для каждого поддомена необходимо создать свой роботс и положить его в соответствующую папку. Т.е. путь к нему должен быть таким:
https://prefix.site.com/robots.txt
https://prefix.site.com/robots.txt
Перечисленные правила носят исключительно рекомендательный характер. Закрытие страницы либо раздела от "глаз" поисковиков не гарантируют того, что в результате страница не будет проиндексирована и не попадет в поисковую выдачу. Основное назначение роботс в помощи индексируемым роботам более оптимально обработать страницы сайта, не тратя свое время и ресурсы на технические страницы. Отсутствие файла robots.txt в последствии может обернуться повышенной нагрузкой на сервер, не полной и замедленной обработки URL поисковыми роботами. Неправильная настройка чревата полной пропаже веб-ресурса из поисковой выдачи.
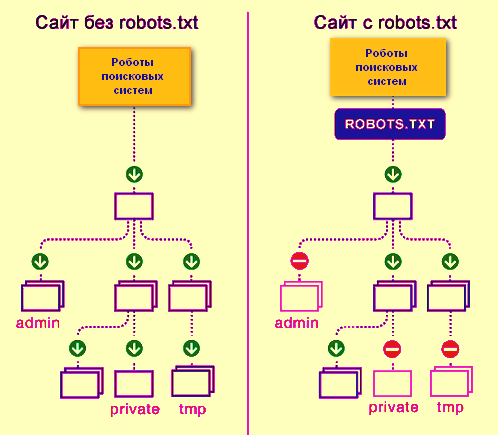
Пример работы robots.txt
Директивы robots.txt
Директивы robots.txt — это набор инструкций, которыми руководствуются индексирующие роботы при посещении сайта. С их помощью можно закрыть определенные страницы или разделы от индексации, управлять скоростью обхода, указать ссылку на sitemap и т.д. Каждая директива должна прописываться с новой строки. После указания директивы ставиться двоеточие и далее прописывается её параметр.
Рассмотрим директивы подробнее.
Рассмотрим директивы подробнее.
User-agent robots txt
User-agent robots.txt - директива определяет для какого робота применимы указанные правила обхода страниц. Допустимо использовать сразу несколько директив User-agent. Чтобы задать инструкцию для всех поисковых роботов, в качестве параметра следует указать символ звездочка:
User-agent: *
Ниже приведена таблица самых распространенных веб-краулеров.
User-agent: *
Ниже приведена таблица самых распространенных веб-краулеров.
Robots txt disallow
Директива Disallow запрещает веб-краулерам индексировать страницу либо раздел. Наиболее часто используемая инструкция в файле robots.txt. С его помощью можно полностью закрыть сайт от индексации:
User-agent: *
Disallow: /
или от конкретного робота поисковой системы:
User-agent: Googlebot
Disallow: /
В качестве параметра следует использовать относительный путь к директории или странице (без указания доменного имени).
User-agent: *
Disallow: /
или от конкретного робота поисковой системы:
User-agent: Googlebot
Disallow: /
В качестве параметра следует использовать относительный путь к директории или странице (без указания доменного имени).
Важно! Пустой параметр в директиве Disallow разрешает индексацию всего сайта:
User-agent: *
Disallow:
User-agent: *
Disallow:
Robots txt allow
Директива Allow в robots.txt является разрешающей инструкцией для веб-краулеров. Очень полезна в случае, когда нам необходимо точечно открыть страницы / подразделы в закрытой директории сайта. Например:
User-agent: *
Disallow: /
Allow: /content
В приведенном примере директива Allow принудительно откроет роботам доступ к индексации страниц, начинающихся с /content, при этом весь остальной сайт будет закрыт от индексации.
User-agent: *
Disallow: /
Allow: /content
В приведенном примере директива Allow принудительно откроет роботам доступ к индексации страниц, начинающихся с /content, при этом весь остальной сайт будет закрыт от индексации.
Важно! Пустой параметр в директиве Allow запрещает индексацию всего сайта:
User-agent: *
Allow:
Равносильно:
User-agent: *
Disallow: /
User-agent: *
Allow:
Равносильно:
User-agent: *
Disallow: /
Clean-param robots txt
Директива Clean-param в robots.txt позволяет исключить из индексации веб-краулерами страницы с динамически генерируемым параметрами в URL. Использование Clean-param в файле robots.txt поможет исключить из индексации дубли страниц, генерирующиеся для реферальных ссылок, UTM-меток, при записи сессий и параметров пользователя.
К примеру мы имеем сгенерированный УРЛы с динамической записью параметра пользователя:
https://site.com/catalog/index.php?&id=1¶m=2
https://site.com/catalog/index.php?&id=2¶m=2
https://site.com/catalog/index.php?&id=3¶m=3
В данном случае нам необходимо составить правило для исключения получившихся параметров. Запись в файле роботс будет такой:
User-agent: *
Clean-Param: &id¶m /catalog/index.php
В результате такой строки индексироваться будет только страница https://site.com/catalog/index.php
С помощью Clean-param можно закрыть от индексации не только отдельные страницы, но и UTM-метки либо идентификаторы пользователей для всего сайта
Clean-Param: utm_source&utm_medium&utm_campaign
К примеру мы имеем сгенерированный УРЛы с динамической записью параметра пользователя:
https://site.com/catalog/index.php?&id=1¶m=2
https://site.com/catalog/index.php?&id=2¶m=2
https://site.com/catalog/index.php?&id=3¶m=3
В данном случае нам необходимо составить правило для исключения получившихся параметров. Запись в файле роботс будет такой:
User-agent: *
Clean-Param: &id¶m /catalog/index.php
В результате такой строки индексироваться будет только страница https://site.com/catalog/index.php
С помощью Clean-param можно закрыть от индексации не только отдельные страницы, но и UTM-метки либо идентификаторы пользователей для всего сайта
Clean-Param: utm_source&utm_medium&utm_campaign
Важно! Директива Clean-Param поддерживается только User-agent: Yandex.
Crawl-delay robots.txt
Директива Crawl-delay в robots.txt позволяет управлять задержками между запросами веб-краулеров к страницам на веб-сервере. В качестве параметров можно указывать целые числа и десятичные дроби (точка в качестве разделителя). Единица измерения — секунды. Директива Crawl-delay поддерживается роботами Яндекс, Mail.Ru, Bing и Yahoo!.
Используется в случае если сервер не выдерживает частоту обращений поисковых роботов. Актуально в случае, когда веб-ресурс состоит из большого числа страниц и слабом веб-сервере.
Рекомендуется начинать применять минимальные параметры, постепенно их увеличивая при необходимости. Для неприоритетных поисковых систем можно изначально задать параметр "с запасом", чтобы исключить их влияние на стабильность сервера.
Пример:
User-agent: Yandex
Crawl-delay: 0.5
User-agent: Mail.Ru
Crawl-delay: 3
Тут мы задали задержку между запросами для Яндекс в пол секунды, а для Мэйл.ру — 3 секунды.
Используется в случае если сервер не выдерживает частоту обращений поисковых роботов. Актуально в случае, когда веб-ресурс состоит из большого числа страниц и слабом веб-сервере.
Рекомендуется начинать применять минимальные параметры, постепенно их увеличивая при необходимости. Для неприоритетных поисковых систем можно изначально задать параметр "с запасом", чтобы исключить их влияние на стабильность сервера.
Пример:
User-agent: Yandex
Crawl-delay: 0.5
User-agent: Mail.Ru
Crawl-delay: 3
Тут мы задали задержку между запросами для Яндекс в пол секунды, а для Мэйл.ру — 3 секунды.
Robots txt sitemap
Директива Sitemap в robots.txt предназначена для указания пути к XML-файлу Sitemap. В качестве параметра необходимо указывать полный (абсолютный) путь к сайтмап. Указание данной директивы сигнализирует поисковым роботам о наличии карты сайта, что позволяет ускорить обнаружение и индексацию новых страниц. Директива не имеет привязки к конкретному юзер-агенту и может быть указана в любой строке файла роботс. Однако хорошим тоном считается указание сайтмап отдельно от всех директив через пустую строку:
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
User-agent: Googlebot
Allow: /
Sitemap: https://site.com/sitemap.xml
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
User-agent: Googlebot
Allow: /
Sitemap: https://site.com/sitemap.xml
Устаревшая директива Host
До 20 марта 2018 года поисковая система Яндекс использовала директиву Host для определения главного зеркала. На данный момент поисковик не учитывает её и рекомендует пользоваться 301 редиректом. Однако в сети интернет по прежнему можно найти массу сайтов у которых директива Host указана.
Пример:
User-agent: Yandex
Disallow: /catalog/
Allow: /catalog/index.php
Host: https://site.com
Пример:
User-agent: Yandex
Disallow: /catalog/
Allow: /catalog/index.php
Host: https://site.com
Прочие директивы robots.txt
Спецификация файла роботс содержит две дополнительные директивы:
- Request-rate: 1/3 ограничивает скорость загрузки страниц, не более одной за три секунды (параметры можно задать любые);
- Visit-time: 0815-1000 определяет временной интервал по гринвичу, в который веб-краулерам разрешено индексировать страницы ( в примере это промежуток с 08:15 по 10:00).
Однако на данный момент они не поддерживаются ведущими поисковыми системами и их использование не имеет смысла.
- Request-rate: 1/3 ограничивает скорость загрузки страниц, не более одной за три секунды (параметры можно задать любые);
- Visit-time: 0815-1000 определяет временной интервал по гринвичу, в который веб-краулерам разрешено индексировать страницы ( в примере это промежуток с 08:15 по 10:00).
Однако на данный момент они не поддерживаются ведущими поисковыми системами и их использование не имеет смысла.
Использование регулярных выражений
В файле robots.txt для более гибкой настройки параметров директив часто используются спецсимволы, которые значительно расширяют функционал. К ним относятся:
1. * (звездочка) определяет любую последовательность символов в том месте, где она указана.
В конце строки звездочка не обязательна, т.к. роботы предполагают её наличие по умолчанию.
В качестве примера
User-agent: *
Disallow: /catalog/*
Allow: /catalog/*.css
Allow: /catalog/*.php
Будут закрыты от индексации все подразделы и страницы раздела catalog, кроме вложенных в корень раздела файлов с расширением .css и .php
Важно! При этом следует понимать, что файлы /catalog/file/index.css и /catalog/file/index.css будут по прежнему закрыты от индексации, так как они лежат в подкатегории file и на них не распространяется директива Allow.
2. $ (знак доллара) используется для ограничения действия спецсимвола *. Означает, что символ перед ним является последним. Позволяет задать точное значения параметра директивы.
Например в robots указано:
User-agent: *
Disallow: /catalog/$
Данная запись исключает индексацию только страницы https://site.com/catalog/, но при этом все вложенные страницы будут открыты веб-краулерам (https://site.com/catalog/index.php).
1. * (звездочка) определяет любую последовательность символов в том месте, где она указана.
В конце строки звездочка не обязательна, т.к. роботы предполагают её наличие по умолчанию.
В качестве примера
User-agent: *
Disallow: /catalog/*
Allow: /catalog/*.css
Allow: /catalog/*.php
Будут закрыты от индексации все подразделы и страницы раздела catalog, кроме вложенных в корень раздела файлов с расширением .css и .php
Важно! При этом следует понимать, что файлы /catalog/file/index.css и /catalog/file/index.css будут по прежнему закрыты от индексации, так как они лежат в подкатегории file и на них не распространяется директива Allow.
2. $ (знак доллара) используется для ограничения действия спецсимвола *. Означает, что символ перед ним является последним. Позволяет задать точное значения параметра директивы.
Например в robots указано:
User-agent: *
Disallow: /catalog/$
Данная запись исключает индексацию только страницы https://site.com/catalog/, но при этом все вложенные страницы будут открыты веб-краулерам (https://site.com/catalog/index.php).
Комментирование в файле robots.txt
В robots.txt для удобства предусмотрена возможность оставлять комментарии, которые полностью игнорируются поисковыми роботами. Для вставки комментария в начале строки указывается спецсимвол # (решетка). Все, что будет написано после него будет пропущено до следующего переноса строки. Если необходимо оставить комментарий на несколько строк, тогда следует указывать решетку в начале каждой строки:
# comment1
# comment2
# comment3
User-agent: *
Disallow:
Использование комментариев позволяет упростить дальнейшую работу с файлом роботс, либо оставить пометки коллегам при совместной работе с сайтом, особенно когда используется большое число директив и беглым взглядом сложно понять какая цель преследовалась при закрытии/открытии отдельных разделов. Еще, к примеру, популярный сайт https://www.tripadvisor.ru/ использует комментарии для оригинального поиска СЕО-специалистов.
# comment1
# comment2
# comment3
User-agent: *
Disallow:
Использование комментариев позволяет упростить дальнейшую работу с файлом роботс, либо оставить пометки коллегам при совместной работе с сайтом, особенно когда используется большое число директив и беглым взглядом сложно понять какая цель преследовалась при закрытии/открытии отдельных разделов. Еще, к примеру, популярный сайт https://www.tripadvisor.ru/ использует комментарии для оригинального поиска СЕО-специалистов.
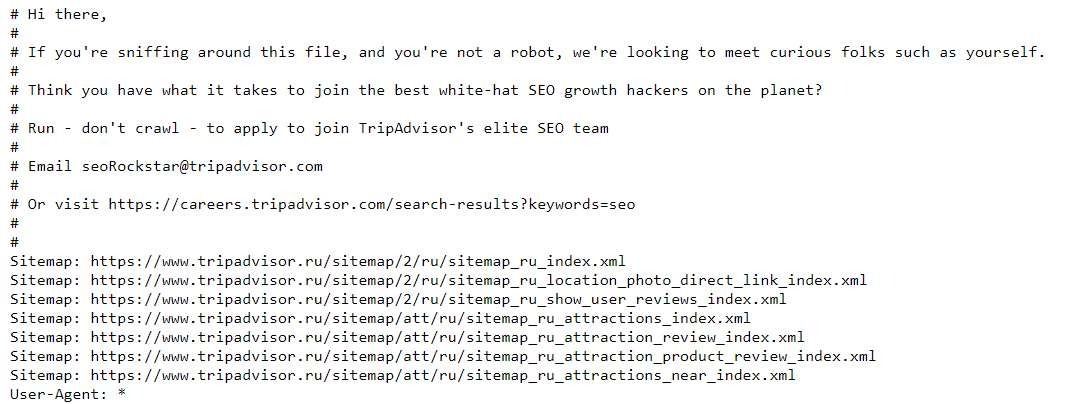
Генерация robots.txt: плюсы и минусы
Для упрощения и ускорения разработки сайта существует множество онлайн-сервисов по генерации файла robots.txt. С их помощью можно быстро создать файл роботс с базовой настройкой правил для поисковых краулеров. Можем рекомендовать к использованию следующие сервисы:
https://pr-cy.ru/robots/
https://tools.seo-auditor.com.ru/robots/
Положительные стороны использования сгенерированных robots.txt:
https://pr-cy.ru/robots/
https://tools.seo-auditor.com.ru/robots/
Положительные стороны использования сгенерированных robots.txt:
- Простота. Выставил необходимые параметры, нажал "сгенерировать", получил готовый файл, который тут же можно заливать в корневую директорию на веб-сервере.
- Нет необходимости настраивать кодировку. Скачанный файл будет гарантированно сохранен в UTF-8.
- Исключена возможность ошибки в названии.
- Возможность проверки срабатывания директив файла robots перед скачиванием.
Как проверить правильную работу файла robots.txt
Онлайн проверка работоспособности файла роботс.тхт осуществляется путем эмулирования отправки запросов индексирующих роботов под нужными User-agent. Проверять можно с помощью доступных инструментов от самих поисковых систем Яндекс и Google:
1. Валидатор robots.txt от Вебмастер Яндекс. Для работы понадобиться быть авторизированным пользователем Яндекс. На странице инструмента необходимо лишь ввести URL и нажать кнопку "Загрузить и анализировать robots.txt с этого сайта".
1. Валидатор robots.txt от Вебмастер Яндекс. Для работы понадобиться быть авторизированным пользователем Яндекс. На странице инструмента необходимо лишь ввести URL и нажать кнопку "Загрузить и анализировать robots.txt с этого сайта".
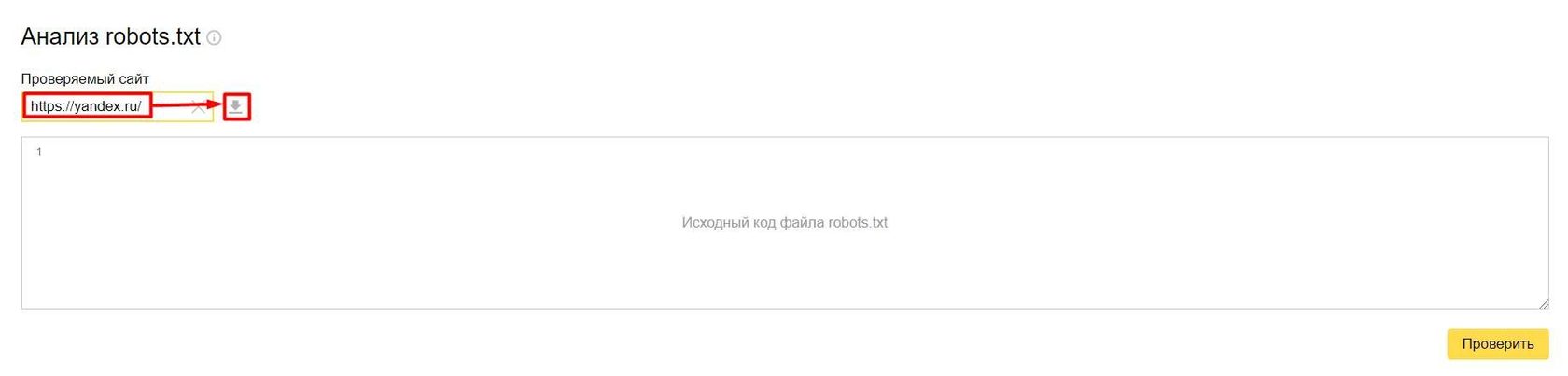
На странице отобразится содержимое рабочего файла роботс с возможностью редактирования и проверки внесенных изменений. Чтобы проанализировать правки необходимо нажать на кнопку "Проверить"

Результат анализа с возможными ошибками отобразится ниже

Также можно проверить доступность списка страниц для робота Яндекс
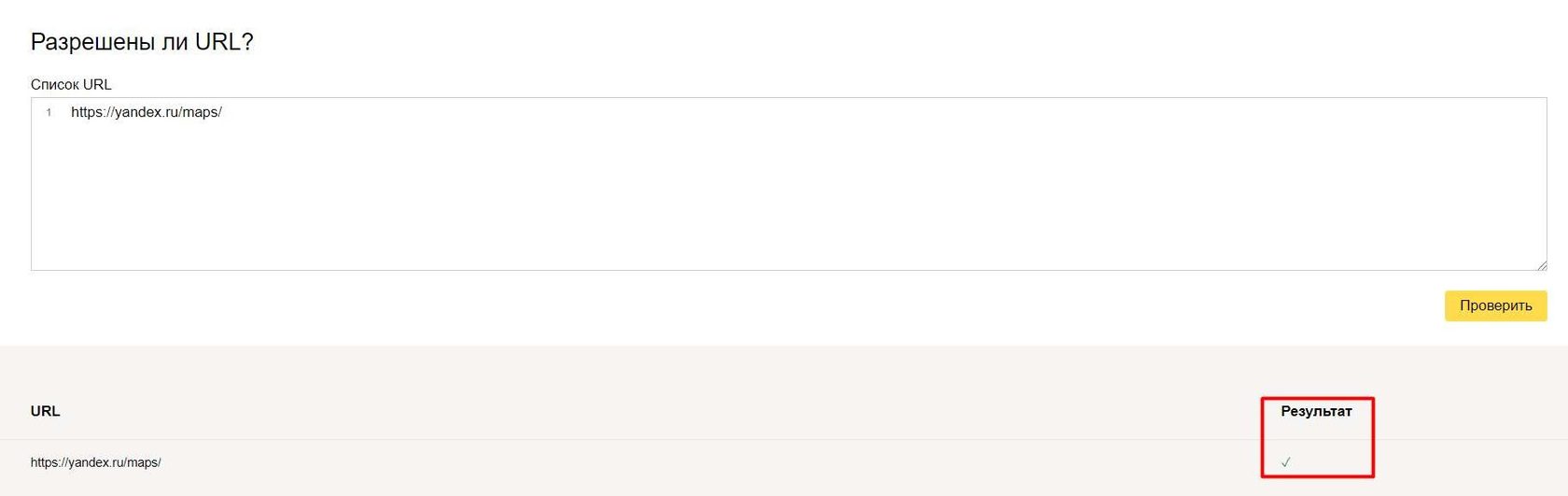
2. Валидатор в Серч Консоли Google. Основным недостатком является необходимость иметь доступ к проекту, следовательно провести анализ чужого сайта не выйдет.
Интерфейс интуитивно понятен. После выбора проекта сразу загружается содержимое файла роботс, отображается информация о доступности и размере файла в байтах, подсвечиваются обнаруженные ошибки и проблемы. Имеется возможность перейти в сам robots.txt на сайте и проверить срабатывание директив для URL. В отличии от Яндекс тут можно указать каким User-agent осуществляется проверка. К сожалению проверить список URL невозможно, необходимо проверять каждую ссылку отдельно.
Интерфейс интуитивно понятен. После выбора проекта сразу загружается содержимое файла роботс, отображается информация о доступности и размере файла в байтах, подсвечиваются обнаруженные ошибки и проблемы. Имеется возможность перейти в сам robots.txt на сайте и проверить срабатывание директив для URL. В отличии от Яндекс тут можно указать каким User-agent осуществляется проверка. К сожалению проверить список URL невозможно, необходимо проверять каждую ссылку отдельно.
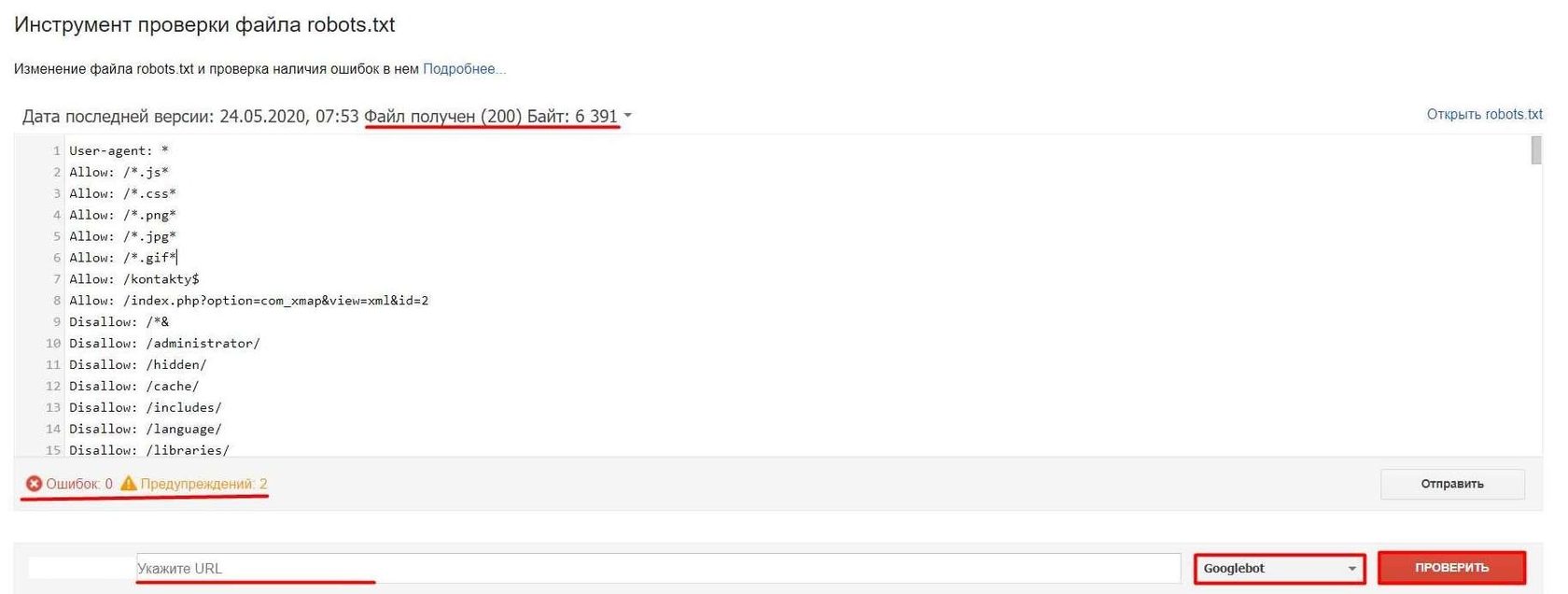
Однако понадобиться проверять роботс в обеих сервисах, так как каждый поисковик поддерживает только свой набор User-agent.
Но к счастью существуют универсальные сервисы проверки Robots, которые позволят проверить работу файла сразу по нескольким поисковикам:
http://tools.discript.ru/robots-check/ — бесплатно, просто проверка
https://tools.pixelplus.ru/news/proverka-robots-txt — инструкция по работе с сервисом. Платно, возможность автоматизации и настройки регулярных проверок.
Но к счастью существуют универсальные сервисы проверки Robots, которые позволят проверить работу файла сразу по нескольким поисковикам:
http://tools.discript.ru/robots-check/ — бесплатно, просто проверка
https://tools.pixelplus.ru/news/proverka-robots-txt — инструкция по работе с сервисом. Платно, возможность автоматизации и настройки регулярных проверок.
Robots txt и CMS
Каждая система управления содержимым (CMS) сайта имеет свои особенности, которые позволяют создать универсальный шаблон файла robots.txt под каждый движок. Это значительно ускоряет и упрощает процесс разработки и оптимизации сайта, позволяя в считанные минуты получить рабочий файл роботс под нужную ЦМС.
В сети интернет можно найти бесчисленное количество наборов директив для robots.txt под каждый CMS. Однако есть более универсальный способ - воспользоваться онлайн-генератором, к примеру:
https://c-wd.ru/tools/robots/
Гибкая настройка директив и возможность выбора популярных CMS помогут создать базовый robots.txt и со старта исключить весь "мусор".
В сети интернет можно найти бесчисленное количество наборов директив для robots.txt под каждый CMS. Однако есть более универсальный способ - воспользоваться онлайн-генератором, к примеру:
https://c-wd.ru/tools/robots/
Гибкая настройка директив и возможность выбора популярных CMS помогут создать базовый robots.txt и со старта исключить весь "мусор".
Внимание! Использование готовых шаблонов файла роботс.тхт подразумевает чистую установку движка без изменения и структуры и подключения сторонних модулей. В противном случае в robots должны быть внесены соответствующие изменения, корректировки, дополнения.
Типичные ошибки при составлении файла robots.txt
Мы собрали список самых распространенных ошибок, которые допускают новички. Все они были взяты из реальных проектов:
- в одной строке размещено несколько директив;
- новая строка начинается с пробела;
- одна директива содержит сразу несколько параметров;
- директива и её параметр расположены в разных строках;
- параметр директивы взят в кавычки;
- добавлен комментарий без знака решетки # в начале строки;
- пустая директива "Disallow: " (забыли указать параметр, в итоге открыли к индексации все страницы);
- пустая директива "Allow: " (забыли указать параметр, в итоге закрыли от индексации все страницы);
- пустая строка внутри одного User-agent (может быть воспринято как завершение текущей директивы юзер-агент);
- название файла robots.txt содержит заглавные буквы или сторонние символы;
- файл роботс весит не более 32 Кб, если есть заинтересованность в ПС Yandex, Google допускает 500 КиБ (Кибибайт);
- пустой robots.txt;
- перечисления директив указаны в строку, без переноса строки;
Наши публикации